
皆の者、ご機嫌麗しゅう!我は、生成AI猫 エルシーじゃ😊
生成AI活用方法を紹介していくのじゃ
基本的な使い方を覚えて、快適な生成AI活用ライフを過ごすのじゃ
出身地:Adobe Firefly(画像生成AI)
皆さん、初めまして!私は、オリバーです。
エルシーさんの助手猫です。
エルシーさんがよく暴走するので、暴走を止める役割をしています。
出身地:Adobe Firefly(画像生成AI)
はじめに
ConoHa AI Canvasで画像生成に挑戦してみました!
しかし、設定の内容や意味がわかりません😢
大丈夫じゃよ!誰でも最初は初心者なのじゃ!
設定の内容について調査してみたのじゃ!
一緒に見てみるのじゃ!
わかりました!設定内容を確認して勉強してみます!
ConoHa AI Canvasのはじめ方については、下記の記事で解説しているのじゃ!
見てくれると嬉しいのじゃ😊
✅ このページは、アフィリエイト広告を利用しています。
🔗 下記リンクは、商品購入などにつながる可能性があります。

WebUIには2種類あります。
今回の設定でご紹介するのは、「Automatic1111(初心者向け)」です。
ConoHa AI Canvasで画像生成:画像生成の指示の仕方【Automatic1111(初心者向け)】
生成AIを使用するときに、指示文の入力欄は1つだけというイメージがありました。
ConoHa AI Canvasでは、2つあるんですね!
その通りじゃ!
それぞれの入力欄では、入力する指示文の種類が異なるから注意が必要なのじゃ!
ポジティブプロンプト
ポジティブプロンプトには、作成した画像の指示文を入力するのじゃ!
こちらの入力欄は、普段我々がよく使う生成AIの入力欄と似ていますね!

ネガティブプロンプト
ネガティブプロンプトは、画像に入れたくない要素を除外するためのものじゃ!
除外するものですか?
具体的には、どんなものが除外対象なのでしょうか?
品質を安定させるために除外するものを指定するのじゃ!
ネガティブプロンプトを入れることで、品質が安定しやすくなるのじゃ!
💥 ⇒ ぼやけた画像を避ける
💥 ⇒ 解像度が低いものを防ぐ
💥 ⇒ 透かし(ウォーターマーク)を排除
💥 ⇒ 手や足が不自然に多い等、AI特有のミスを防ぐ
指示するのって難しいですね!

チェックポイント
チェックポイントと記載があるが、ベースになる学習済みモデルのことじゃよ!
生成する画像の「絵柄・精度・傾向」を決める最重要項目なのじゃ!
そうなんですね!
チェックポイントの名前が長くて複雑ですね!
これにはどんな意味があるのでしょうか?
下記に内容をまとめたのじゃ!
名前を無理に覚えなくても大丈夫なのじゃ!
| 名称部分 | 内容 | 初心者向けの意味 |
|---|---|---|
v1-5 | バージョン1.5のStable Diffusion | 軽くて扱いやすい人気モデル |
pruned | 不要部分を削った軽量版 | 動作が軽くなる(パソコンへの負担が少なめ) |
emaonly | 学習時の平均状態を保存 | 安定した画像が出やすい |
.safetensors | セーフな保存形式 | セキュリティ的にも安心なファイル形式 |
checkpointには、他にも種類があるのでしょうか?
下記の種類があるのじゃ!
※2025年7月27日追記
| モデル名 | 主な用途・特徴 | おすすめの使い方例 |
|---|---|---|
| 512-inpainting-ema | “修復”や“部分生成”向け。既存画像に変更を加えるのが得意 | 顔の修正、背景差し替えなど |
| animagine-xl-4.0 | アニメ風の高品質生成に特化。細部の美しさと色彩表現が魅力 | 美少女イラスト、ファンタジー背景など |
| fudukiMix_v20 | 和風・幻想系の表現が得意。落ち着いたトーンと精密さ | 着物姿、季節感のある風景 |
| realDream_15SD15 | 写実系に寄せた表現力。リアルっぽいけど幻想的な印象もありバランス型 | ファンタジーキャラ、ポートレート |
| sd_xl_base_1.0 | 高解像度ベースモデル。多目的に使える汎用型 | 一枚絵の基盤として安定 |
| sd_xl_refiner_1.0 | Base画像をさらにクオリティアップする“仕上げ役” | 生成後のディテール強化 |
| v1-5-pruned-emaonly-fp16 | 軽量かつ安定した旧世代の人気モデル。処理が速く、初心者にも扱いやすい | キャラ立ち絵、ロゴ風画像など |
| v2-1_768-ema-pruned | V2世代でより高精度な表現。構図やデザインにも強く、抽象表現も◎ | コンセプトアート、風景イラストなど |
| yayoiMix_v25 | 色使いや構図が鮮やかで芸術性が高め。やや幻想的でユニークな描写が得意 | アート作品風、非現実的な世界観 |
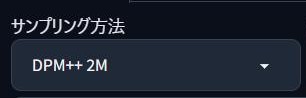
サンプリング方法

サンプリング方法とは、
画像生成の「雰囲気」や「仕上がりの精度」に関わるアルゴリズムのことじゃよ!
種類によって画像の雰囲気が変わるのでしょうか?
そうじゃ!
サンプリング方法について調査してみたのじゃ!
| 🧠 サンプリング方法 | 🔍 内容(初心者向け) |
|---|---|
| 🌿DPM++ 2M | 安定・高速で初心者におすすめ。バランスが良く万能型。 |
| 🔬DPM++ SDE | ノイズ除去に強く、繊細な描写向け。背景や細部が得意。 |
| ⚡DPM++ 2M SDE | 上記2つの良さを併せ持つ。品質と速度の両立型。 |
| 🎯DPM++ 2M SDE Heun | さらに精密な処理。高画質狙い時に◎ |
| 🍃DPM++ 2S a | 柔らかい雰囲気。人物や優しい絵にぴったり。 |
| 🧩DPM++ 3M SDE | 細部重視の高精度型。構図にこだわる方に。 |
| 🎨Euler a | 遊び心あり。ややランダムな柔らかい生成。 |
| 📐Euler | 構図がはっきり出る。シャープで明瞭な絵向け。 |
| 🧱LMS | やや古めの手法。素朴な描写向け。 |
| 🏗️Heun | 線が太く力強く出る。構造物などに◎ |
| 🚀DPM2 | 軽量&高速。手早く絵を出したいときに。 |
| 🔧DPM2 a | DPM2の強化版。少しだけ高品質。 |
| ⚙️DPM fast | スピード重視。試行回数を増やしたいときに。 |
| 🛠️DPM adaptive | 自動で最適化。初心者にもやさしい選択肢。 |
| ♻️Restart | 特殊処理。通常の使用では不要。 |
| 🌀DDIM | なめらかでアニメ調の描写に向いている。 |
| 🔗DDIM CFG++ | 指示文との一致度を強化。厳密に描きたいときに。 |
| 📎PLMS | 安定重視。品質を落とさず丁寧に出力。 |
| 🧪UniPC | 進化型の高精度サンプラー。こだわり派向け。 |
| ⚡LCM | 超高速生成。リアルタイム系や多枚数出力に。 |
Schedule Type
Schedule Typeとは、特定のアルゴリズムで必要なタイミング調整のタイプのことじゃよ!
| 📋 Schedule Type | 🧠 内容(初心者向け解説) |
|---|---|
| ✅自動(Automatic) | 使っているサンプリング方法に合わせて最適設定を自動で選んでくれます。初心者はこれでOK! |
| ⚖️Uniform | 処理を均等に分配。安定性重視だが、表現が単調になることも。 |
| 🎯Karras | 人気のある滑らか描写型。自然な雰囲気が出やすく、初心者にもおすすめ✨ |
| 📈Exponential | 処理を後半に集中。繊細な絵や雰囲気重視に◎ |
| 📉Polyexponential | Exponentialを強化した方式。さらに後半処理偏重。 |
| 🌐SGM Uniform | SGMモデル向け。均等分配型で素朴な描写になることが多め。 |
| 🧪KL Optimal | ノイズ除去に理論的な最適配分を行う高精度タイプ。こだわり派向き。 |
| 🧭Align Your Steps | 描画工程(ステップ)を整えて滑らかな画像に。安定性寄り。 |
| 🚀Simple | 複雑な処理なしで手早く描画。試行回数を増やしたいときに便利 |
| 📊標準正規分布(Normal) | 統計に基づいて平均的に分配。バランス型で初心者にも扱いやすい。 |
| 🎞️DDIM | DDIMサンプリング用。なめらか&アニメ調の描写に向いています。 |
| 🧬Beta | ベータ分布による調整方式。高度な理論型でプロ向け。 |
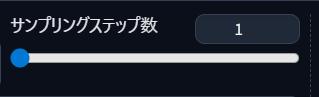
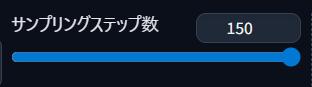
サンプリングステップ数
サンプリングステップ数は、画像を何回精密に作り込むか設定するのじゃ!
多いほど高画質じゃが、生成するのに時間がかかるのじゃ😢
初心者におすすめの値はどれくらいですか?
20~30じゃよ!
慣れてきたら増やしてもOKじゃ!
高解像度補助
画像の解像度を後からアップスケールする機能のことじゃ!
高解像度ということは時間がかかるということですね!
高画質にしなくていい場合は、チェックは不要ですね!
高解像度補助を使うと処理に時間がかかるので注意じゃ!
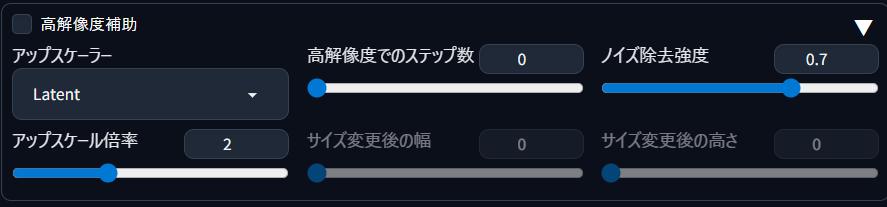
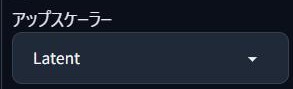
【高解像度補助】アップスケーラー
解像度を高くする方式のことじゃ!
「Latent」なら精度と速度のバランスが◎じゃよ😊
悩んだら「Latent」にすればいいんですね!
| アップスケーラー名 | 内容(初心者向け説明) |
|---|---|
| 🧠 Latent | 標準的なAI補正。描き込みが増えてリッチな仕上がり。速度も速くて万能型。 |
| 🫧 Latent(アンチエイリアス補間) | ギザギザをなめらかに補正。線が柔らかくなる。 |
| 🌀 Latent(バイキュービック補間) | Photoshopなどでも使われる方式。自然なぼかしで拡大。 |
| 🧪 Latent(バイキュービック+アンチエイリアス) | 上記2つの合わせ技。なめらか&自然な拡大。 |
| 🕹️ Latent(ニアレスト補間) | ドット絵風に拡大。画素をそのまま引き伸ばす感じ。 |
| 🔳 Latent(ニアレスト-エグザクト補間) | より正確なニアレスト方式。ドット絵やレトロ風に◎ |
| 🚫 なし(None) | アップスケーラーを使わずにそのまま拡大。画質は劣化しやすい。 |
| 📷 Lanczos | 高精度な補間方式。写真や実写系に向いている。 |
| 🔲 Nearest | ニアレスト補間の別バージョン。ドット絵やピクセルアート向き。 |
| ⚡ DAT x2 / x3 / x4 | 高速アップスケーラー。倍率ごとに選べる。処理が軽くて速い。 |
| 🎯 ESRGAN_4x | AI補正で高画質化。自然な描写で写真にもイラストにも使える。 |
| 🔬 LDSR | 動画や低画質画像の補正に強い。細部を復元する力がある。 |
| 🚀 R-ESRGAN 4x+ | ESRGANの強化版。実写・AI画像の補正に優秀。 |
| 🎌 R-ESRGAN 4x+ Anime6B | アニメ特化型。線や色がくっきり出る。アニメ絵に最適✨ |
| 🎨 ScuNET GAN | GAN方式で自然な補正。やや柔らかめの仕上がり。 |
| 🛡️ ScuNET PSNR | ノイズ除去に強い。写真や実写系に向いている。 |
| 🌄 SwinIR 4x | 高精度なAI補正。細部の描写が得意で、実写・風景に◎ |
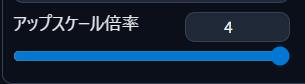
【高解像度補助】アップスケール倍率
どのくらいの大きさにするかを設定するのじゃ
(例:×2で倍のサイズ)
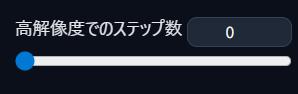
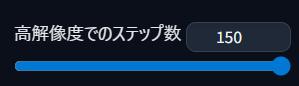
【高解像度補助】高解像度でのステップ数
高解像度処理時に何回描画するか(ステップ数)を設定するのじゃ
「0〜12」がおすすめです!
数が低めなら高速で処理されます。
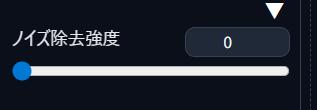
【高解像度補助】ノイズ除去強度
元画像の描き直し度のことじゃ!
この数値が高いほど、良い画像ができるのでしょうか?
そうではないのじゃ😢
高いほど再描画が強いのじゃが、不自然になることもあるのじゃ
「0.6〜0.7」が安定しやすいのじゃ
【高解像度補助】サイズ変更後の幅・高さ
最終的な画像サイズのことじゃ
基本は自動でOKじゃよ!
手動入力しなくてOKです!
倍率に連動します。

Refiner
SDXL(Stable Diffusion XL)専用の仕上げ補正機能のことじゃ!
SDXL(Stable Diffusion XL)とは何ですか?
SDXL(Stable Diffusion XL)は、画像生成AIの進化版なのじゃ!
より高精細な画像を作れるモデルのことじゃ!
具体的にどんな時に使うものですか?
Baseモデルで作った画像に対して、下記の仕上げをしたい場合に使うのじゃ
- 肌や髪の質感を自然に整える
- 光と影のコントラストを調整
- 背景のぼかし具合を微調整
- 色味や立体感をより鮮やかに演出
料理の最後の味付けみたいなものですね😊

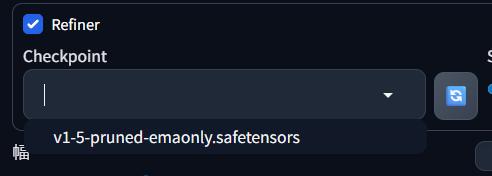
【Refiner】Checkpoint
Checkpointでは、AIが画像を描くときに使うモデルを設定するのじゃ
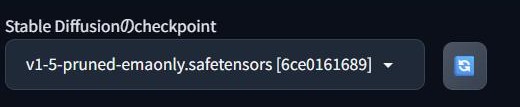
スクショに表示されているのが「v1-5-pruned-emaonly.safetensors」というモデルなんですね!
このモデルはどんな内容ですか?
モデルの意味は下記の通りじゃ!
・v1-5:Stable Diffusionのバージョン1.5
・pruned:不要な部分を削除した軽量モデル(使いやすく調整済み)
・emaonly:学習時の平均的な状態(Exponential Moving Average)で保存されたモデル。
checkpointには、他にも種類があるのでしょうか?
下記の種類があるのじゃ!
※2025年7月27日追記
| チェックポイント名 | 特徴・用途 | 対応モデル | スタイル・得意分野 |
|---|---|---|---|
| 512-inpainting-ema | 画像の一部を修正・補完する「インペイント」専用モデル | SD1.5 | 部分修正・自然なつなぎ目 |
| animagine-xl-4.0 | 高品質なアニメ風画像を生成できる人気モデル | SDXL | アニメキャラ・ゲーム風 |
| fudukiMix_v20 | 日本人の顔や雰囲気に特化したリアル系モデル | SDXL | 和風・リアル人物 |
| realDream_15SD15 | 写真のようなリアルな描写が得意 | SD1.5 | 写実的・人物・風景 |
| sd_xl_base_1.0 | SDXLの基本モデル。高解像度画像の生成に最適 | SDXL | ベースモデル(万能型) |
| sd_xl_refiner_1.0 | SDXLで生成した画像をさらに美しく仕上げる補助モデル | SDXL | 仕上げ・細部強化 |
| v1-5-pruned-emaonly-fp16 | 軽量化されたSD1.5モデル。動作が軽く初心者向け | SD1.5 | 汎用・高速生成 |
| v2-1_768-ema-pruned | SD2.1対応。より高精度な画像生成が可能 | SD2.1 | 高精細・リアル系 |
| yayoiMix_v25 | アニメとリアルの中間。柔らかい雰囲気が特徴 | SDXL | 混合スタイル・女性キャラ |
| v1-5-pruned-emaonly | SD1.5の標準モデル。多くのLoRAと互換性あり | SD1.5 | 基本・安定性重視 |
【Refiner】Switch at
Stable Diffusion XL(SDXL)では、
画像の初期生成を通常モデルで行い、その後にRefinerモデルで仕上げを加えるというステップがあるのじゃ!
そんな仕組みだったんですねΣ(・□・;)
初期生成ということは、どこかで切り替えるポイントを決める必要があるということですね?
そうなのじゃ!
「Switch at」で、どの段階でRefinerに切り替えるのかを決めるのじゃ!
| 数値 | 意味 | 特徴 |
|---|---|---|
| 0.01(画像の設定) | ほぼ最初からRefiner使用 | より滑らかで高精度な仕上がり |
| 0.5 | 中間で切り替え | 通常モデルとRefinerのバランス型 |
| 0.8〜0.9 | 最後の仕上げだけRefiner | 元画像の雰囲気が強く残る |
幅と高さ
生成される画像のサイズ(px)のことじゃ
512×512が標準サイズとなります。


CGFスケール
指示文(プロンプト)にどれだけ忠実に画像を生成するかについて設定するのじゃ
値が高いほど、指示に強く従うということですね!
値を最大にすればいいのですか?
最大にすればいいというものではないのじゃ😢
値が高いほど指示に忠実になるのじゃが、不自然になる場合もあるのじゃ!
加減が難しいですね!
「7」くらいがちょうどいいと言われているのじゃ!


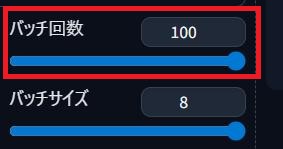
バッチ回数
何回繰り返して画像を生成するか設定するのじゃ!
バッチ回数が「2」であれば、2回繰り返して画像を生成するということですね!

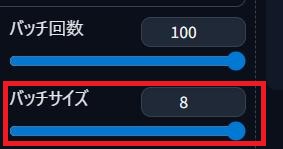
バッチサイズ
1回の処理で、何枚の画像を同時に作るのか設定するのじゃ
「2」であれば、1回の処理で2枚作成されるということですね

ここで注意点じゃ!
バッチ回数×バッチサイズで生成される画像の枚数が決まるのじゃ!
バッチ回数×バッチサイズが大きくなると時間がかかるのじゃ!
バッチ回数=1、バッチサイズ=2の場合、
1×2=2枚ということですね!
シード
シード値とは、ランダムの起点番号のことじゃよ!
同じ指示文であっても、シードの値が異なると違う画像になるのじゃ!
同じ画像を再現したいのであれば、同じ番号を使う必要あるのですね!
その通りじゃ!
ただし、同じシートの値でも完全一致にはならないので注意が必要なのじゃ!
「-1」の意味は何ですか?
毎回ランダムなシードを自動生成するという意味じゃ!
毎回違う画像を作成したいのであれば、「-1」でOKじゃ!
基本的には「-1」で良さそうですね!
隣のサイコロやリセットマークにも意味があるのでしょうか?
下記の操作を行う時に使うのじゃ!
🎲 サイコロマーク → ランダムなSeedを生成
🔄 リセットマーク → 前回のSeedに戻す(再現したいときに使う)
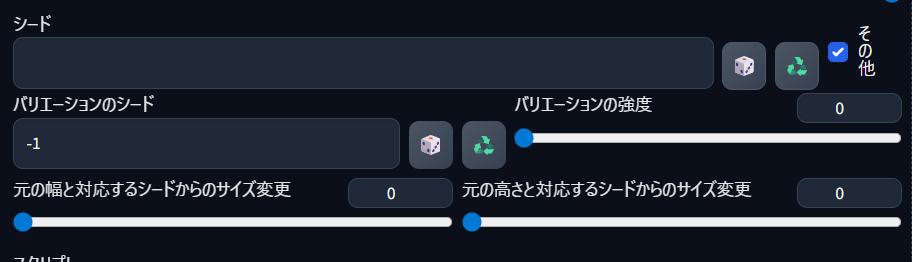
バリエーションの強度
下記について設定を行うものじゃ!
・元画像の特徴をどのくらい残すのか?
・元画像からどのくらい変化させるのか?
数値はどのように設定すればいいのでしょうか?
下記の表を参考に設定するといいのじゃ!
同じ画像でよければ「0」、変化させたい場合は数値を大きくすればいいですね!
| Variation strength | 変化の度合い | 特徴 |
|---|---|---|
| 0 | ほぼ同じ | 元画像とほぼ一致。再現目的に◎ |
| 0.1〜0.2 | 少し変化 | 髪型・服装・背景などが微調整される |
| 0.5 | 中程度の変化 | ポーズや構図も変わる可能性あり |
| 1.0 | 大きく変化 | ランダム性が強く、別物になることも |
元の幅・高さと対応するシードからのサイズ変更
同じシードから出る画像を少しサイズ変化させたい場合に使う設定なのじゃ!
サイズを変化させたくない場合は、0ということですね?
その通りじゃ!
下記の表を参考にしてほしいのじゃ!
| 項目 | 設定値「0」の意味 | 設定値を上げると? |
|---|---|---|
| 幅シード補正 | 幅は変化せず固定サイズ | 幅にランダムなズレが加わる(例:少し広めに) |
| 高さシード補正 | 高さも変化なし | 高さに揺らぎが出る(例:少し縦長になる) |
下記の場合に、設定の値を変えるといいと思います。
・複数枚の画像を一括生成したとき、少しずつサイズを変えてランダム感を出したいとき
・特定の演出(画角バリエーション)や、画像配置の微差を楽しみたいとき
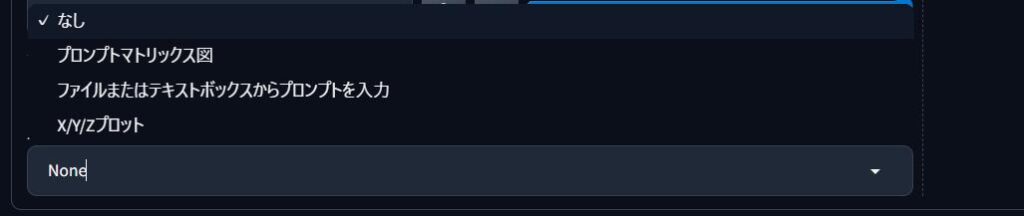
スクリプト
画像生成時に特殊な動作や自動処理を追加できる機能なのじゃ!
特にこだわりがなければ、「None(なし)」で問題ないんですね!

| 選択肢 | 初心者向けの説明 | よく使う場面例 |
|---|---|---|
| なし(None) | 特別なモードは使わず、通常どおり画像を作成 | はじめての方はこれでOK! |
| プロンプトマトリックス図 | 複数の単語やフレーズを自動で組み合わせて画像を生成 | どの表現が一番いいか比較したいとき |
| ファイルまたはテキストボックスからプロンプトを入力 | 外部ファイルや長文プロンプトを使って画像生成 | たくさんのプロンプトを一気に使いたいとき |
| X/Y/Zプロット | 複数の設定項目(例:明るさ×構図など)を比較しながら生成 | マニアックな検証や実験に便利 |
タブ
画面の下にあるタブは何ですか?
いろんな種類のタブがありますよね?
タブの内容をこちらにまとめたのじゃ!
基本的に画像を生成する場合は、「Generation」で十分そうですね!
こだわりたい場合は、他のタブを適宜活用すれば良さそうです!
| タブ名 | 初心者向けの説明 | よく使われる目的 |
|---|---|---|
| Generation | 通常の画像を生成する場所 | プロンプト入力 → 画像生成を行う |
| Textual Inversion | 独自の単語(タグ)に学習させたモデルを使う | 「◯◯風」のイメージを再現するための学習モデル |
| Hypernetworks | モデルに柔軟性を加える技術 | 特定の絵柄やスタイルを強調した画像を作る |
| Checkpoints | 使うべき基本モデルの選択場所 | キャラ絵/写真風など、方向性を決める元になる |
| LoRA | 軽量のカスタムモデルを追加できる | 細かい表現(髪型・衣装など)を微調整する目的など |
まとめ・PR
ConoHa AI Canvasは有料なのじゃ!
自分にあった生成AIなのか確認してから使ってほしいのじゃ!
月額料金とは別に、WebUIの無料枠を超過した分について「6.6円/分」課金される仕組みです。
下記の記事で注意点をご確認ください。
✅ このページは、アフィリエイト広告を利用しています。
🔗 下記リンクは、商品購入などにつながる可能性があります。


コメント